# Text Annotation
## Text annotation for NLP and document processing: a complete guide
Text annotation is widely used in organisations to solve NLP tasks for machine learning models. Learn more about text annotation in machine learning and how to employ the tool for better productivity!
### What is Text Annotation in Machine Learning?
Simply put, text annotation in machine learning (ML) is the process of assigning labels to a digital file or document and its content. Labeling a text can consist in assigning tags to text attributes such as keywords, sentences, and paragraphs or simply classifying the text based on its content (i.e. text classification).
These include various NLP technologies like neural machine translation (NMT) programs, auto Q\&A (question and answer) platforms, smart chatbots, sentiment analysis, text-to-speech synthesizers, and auto speech recognition (ASR) tools, among other related projects. These technologies can streamline the activities and transactions of many organizations across different industries.
If you want to learn more about the history of NLP in computer science, you can read [our article](https://kili-technology.com/data-labeling/nlp/learn-more-about-deep-learning-and-natural-language-processing) here.
### What are the different types of text annotations?
#### Text / Document classification
Text and document classification consists in attributing one or multiple attributes to a single text or full document.
Examples:
1. 1\. Classifying emails as spam or regular emails
2. 2\. Doing sentiment analysis on tweets
3. 3\. Labeling legal documents based on their content (legal notices, agreements, bonds, …)

Example of sentiment analysis on an amazon review

Bill of lading being classified
#### Named entity recognition
At a high level, named entity recognition is the action of identifying named entities within a text and assigning it a predefined category. Common categories that are used for this type of text annotation include names of organizations, locations, persons, numerical values, month or time and day of the week, etc. But depending on the type of NER performed, categories such as paragraph, title, and content can also be used.

NER performed on a short article from Reuters
#### Entity linking
This is the process for linking entities to better understand the structure of the text and the relationships between entities. Here you can see a table being extracted from a scanned invoice and item lines being linked together to preserve its structure.\
\

A table being extracted from scanned document

A table being extracted from scanned document
#### Layout analysis
Layout analysis consists of labeling document structures to transform them into another format (ex: JSON).

Layout analysis consists of labeling document structures to transform them into another format (ex: JSON).
### How to label texts, PDFs, and Images?
In real life, textual data exists under a wide range of different formats txt, pdf or even text in images or scanned documents. In this part are going to dive deep into the specificities of those data formats and what features are mandatory to label efficiently.
### Labeling text data
When labeling text data in simple txt format, the following features are important:
#### Multilingual Support
When labeling textual data, language and tokenization are key to consider. The labeling tool used must allow the labeling of all languages. Using Kili, you can natively label any language using our interfaces.\

Annotated English Document

Annotated Arabic Document
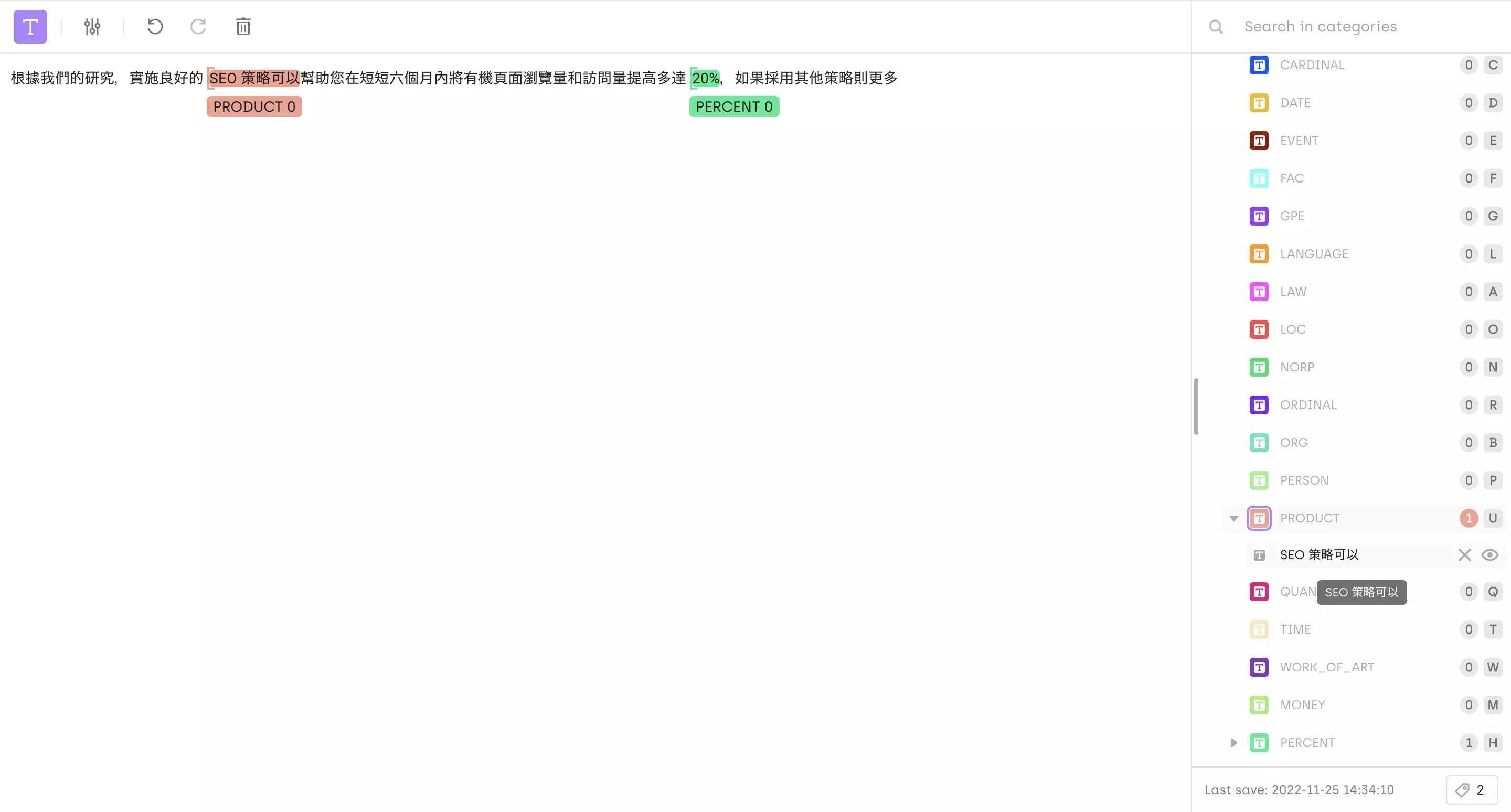
Annotated Chinese-speaking Document
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://metaverse-imagen.gitbook.io/ai-tools-research/about-ai-tools-research/frequently-asked-questions-faqs/faqs-on-llm-training-and-data-labelling/building-datasets/text-annotation.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.