How to Fine Tune LLMs?
How to fine tune large language models (LLMs)
How to fine tune large language models (LLMs) with Kili Technology
Learn how to fine-tune large language models (LLMs) for specific tasks using Kili Technology. This tutorial provides a step-by-step guide and example on fine-tuning OpenAI models to categorize news articles into predefined categories.

Table of Contents
What are large language models (LLMs)?
Let’s start our tutorial by explaining LLMs. Large Language Models (LLMs) are a class of machine learning models that are capable of processing and generating natural language text. These models are trained on massive amounts of text data, often using unsupervised learning techniques, to learn patterns and representations of language.
Large language models are distinguished by their size and complexity, with billions of parameters, making them some of the most powerful AI systems developed to date.
Some examples of large language models include OpenAI's GPT-3, Google's T5, and Facebook's RoBERTa. These models have been shown to excel at a wide range of natural language processing tasks, including text classification, language translation, and question-answering. But as you may have experienced, these large language models may struggle with more industry-specific cases and will require additional training to be effective for more particular applications.
LLMs are typically trained using massive amounts of text data, such as web pages, books, and other sources of human-generated text. This allows the models to learn patterns and structures in language that can be applied to a wide range of tasks without needing to be retrained from scratch.
The ability to transfer knowledge from pre-training to downstream tasks is one of the critical advantages of LLMs, and it has led to significant advances in natural language processing in recent years.
Fine-tuning a Large Language Model
What is Fine-tuning?
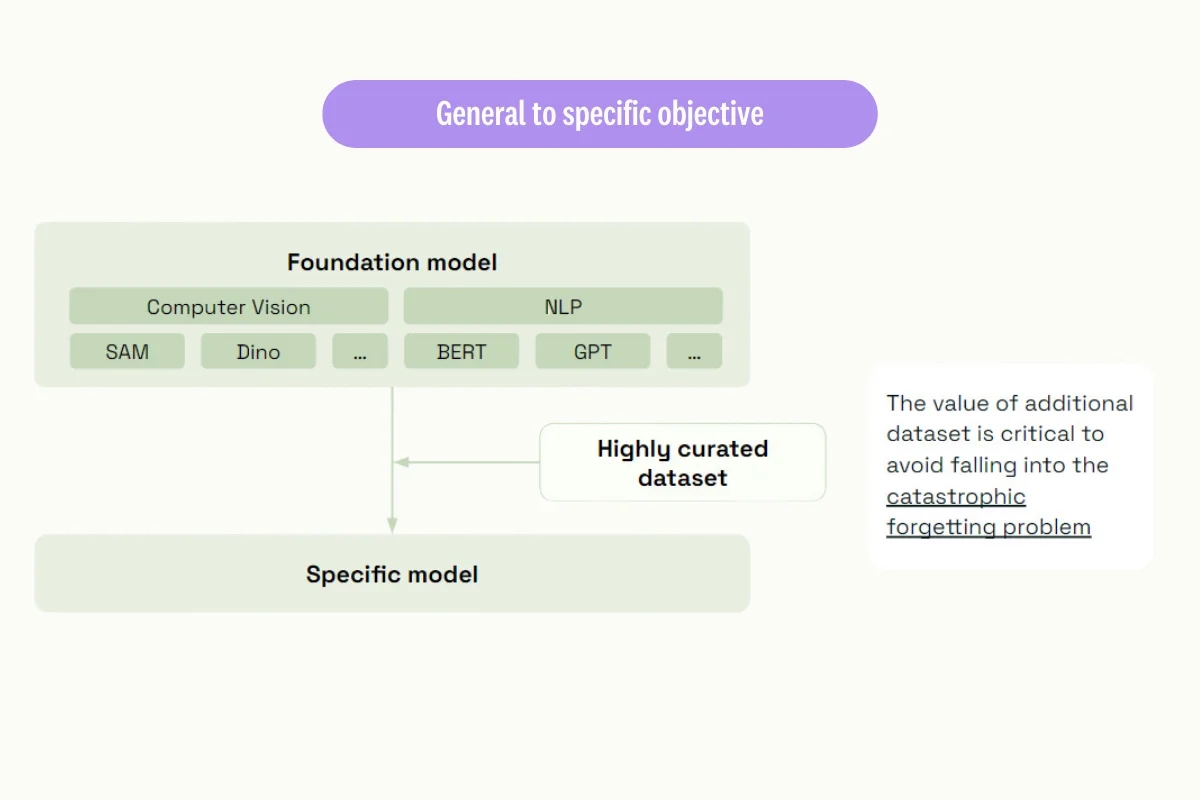
Fine-tuning is a technique in machine learning used to adapt a pre-trained model to perform better on a specific task. The idea behind fine-tuning is to leverage the knowledge and representations learned by the pre-trained model and then further optimize the model's parameters for the new task.
The process of fine-tuning typically involves the following steps:
Starting with a pre-trained model, often on a large dataset of data.
Adding a task-specific layer on top of the pre-trained model. This layer is usually a set of trainable parameters that can be optimized for the new task.
Fine-tuning the model on a smaller, task-specific dataset that is labeled with the desired output. During this stage, the parameters of the task-specific layer and the pre-trained model are updated to minimize the difference error between the predicted output and the expected output.
Evaluating the performance of the fine-tuned model on a hold-out test set to ensure it is generalizing well on new examples.
Fine-tuning is a powerful technique in many areas of machine learning, including natural language processing and computer vision. By starting with a pre-trained model and only updating a small set of parameters for a specific task, fine-tuning allows for efficient use of computational resources and can often achieve state-of-the-art results.
What are the Most Common Fine-tuning Methods?
There are several common methods for fine-tuning pre-trained models in machine learning. Here are a few examples:
Linear Fine-Tuning: This is the simplest and most common form of fine-tuning, where a linear layer is added on top of the pre-trained model and then trained for the specific task. In this approach, the pre-trained weights are frozen, and only the weights of the new linear layer are learned from scratch. This technique is often used for text classification and sentiment analysis tasks.
Full Fine-Tuning: In this approach, all the weights of the pre-trained model are fine-tuned on the specific task, including the pre-trained layers. This approach can be more computationally expensive, but it can be effective for tasks that require more nuanced understanding of the input, such as language translation or image captioning.
Gradual Unfreezing: This is a technique where the pre-trained layers are gradually unfrozen and trained on the specific task, starting from the topmost layer and gradually working down to the lower layers. This allows the model to learn task-specific features while retaining the general language or image understanding from pre-training.
Adapter-Based Fine-Tuning: Adapter-based fine-tuning is a recently proposed technique that allows fine-tuning with minimal changes to the pre-trained model. This approach adds a small adapter network to the pre-trained model, which is then trained on the downstream task while the pre-trained model is frozen. This technique can reduce the computational cost and memory requirements of fine-tuning while still achieving competitive results.
These are just a few examples of the many fine-tuning techniques that exist. The choice of the best method depends on the specific task, the available computational resources, and the trade-offs between performance and efficiency.
How do we fine-tune large language models?
Fine-tuning adapts pre-trained LLMs to specific downstream tasks, such as sentiment analysis, text classification, or question-answering. The goal of fine-tuning is to leverage the knowledge and representations of natural language, code (and the list goes on) learned by the LLM during pre-training and apply them to a specific task.
The process of fine-tuning involves taking a pre-trained LLM and training it further on a smaller, task-specific dataset. During fine-tuning, the LLM's parameters are updated based on the specific task and the examples in the task-specific dataset. The model can be customized to perform well on that task by fine-tuning the LLM on the downstream task while still leveraging the representations and knowledge learned during pre-training.
The basic steps of fine-tuning a pre-trained LLM are as follows:
Initialize the large language model with the pre-trained weights.
Add a task-specific head to the large language model.
Train the large language model on the task-specific dataset, updating the weights of both the head and the large language model.
Evaluate the fine-tuned model on a validation set.
Repeat steps 3-4 until the model achieves satisfactory performance.
Fine-tuning has proven to be an effective way to adapt pre-trained LLMs to a wide range of downstream tasks, often achieving state-of-the-art performance with relatively little additional training.
Learn more about how to build domain specific LLMs
Tutorial: Fine-Tuning Large Language Models with Kili Technology
In this tutorial, we will walk you through the process of fine-tuning OpenAI models using Kili Technology. We redirect you to this notebook written by technical writer. It provides a step-by-step guide to building a machine-learning model capable of categorizing short, Twitter-length news into one of eight predefined categories.
You can follow the notebook right after reading this article but for a general idea of what we've done, here's a quick description of the process and what to look out for.
The data
The data we've used is from Kaggle. It's a dataset listing HuffPost's articles published over the course of several years, with links to articles, short descriptions, authors, and dates they were published. The data here is under a 4.0 Creative Commons license which allows us to share and adapt the data however we want, so long as we give appropriate credit.
The objective
Our objective is to fine tune a large language model to assign one of 8 categories to the news items in our dataset. To speed up the process, we removed all the entries with vague categories like IMPACT or PARENTING. This is the final list:
MEDIA & ENTERTAINMENT
WORLD NEWS
CULTURE & ARTS
SCIENCE & TECHNOLOGY
SPORTS
POLITICS
MONEY & BUSINESS
STYLE & BEAUTY
To make matters as simple as possible, the assumption is that one piece of news can match only one of these categories.
OpenAI recommends having a couple of hundred training samples to fine-tune their models effectively. So we collected. To ensure we meet the requirements, we've prepared 4 sample files. Each file contains 100 labeled examples for each of the eight classes. If you need more, you can easily process the original dataset for additional samples.
The model
OpenAI has a number of models and you can find more information about their models here. When you're choosing your own model, take into consideration the costs, maximum tokens, and performance. In our use case we fell back to using Curie, which is an appropriate model that is fast, capable, and costs less than other models.
The steps
As mentioned earlier, you can follow through all the steps through our notebook. The steps outlined here is just to give you an idea of the process.
Setting up - Fine-tuning your model is done via Kili's API, so if you're following along with the notebook, you'll need to have that set-up. If you need guidance, we have handy documentation here.
Create a JSON file for your project's ontology - In our case, we want a classification job that splits things into various categories: media and entertainment, world news, etc. We also want to specify that it should only select one category from the list. We also added an UNABLE_TO_CLASSIFY category for situations when, for whatever reason, the model fails to do the job. Here's what it looks like for us:
3. Extract the data from the curated dataset and upload the news headlines to Kili.
4. Generate predictions using your model - In this tutorial we'll be using one of OpenAI's models. You'll need your OpenAI organization ID and OpenAI API key.
If you're used to GPT and other OpenAI tools at this point, you'll have some experience in writing a good prompt that directly states what you want your LLM to do.
In our case, we used this prompt:
Classify the text of the following message as exactly one of the following: MEDIA AND ENTERTAINMENT, WORLD NEWS, CULTURE AND ARTS, SCIENCE AND TECHNOLOGY, SPORTS, POLITICS, MONEY AND BUSINESS, STYLE AND BEAUTY.
The LLM might want to return more than one category, so make sure to filter that and remember to set the fallback of UNABLE_TO_CLASSIFY. Start with a small set for trial, and once it works, run it on the whole data set.
Here's how we did it with our code:
5.Do some manual human labeling In our notebook, we simulated human labeling, but in real cases manual, the objective of human labeling is to compare the model's performance and ensure the quality of the data labeling. So when putting this into practice, it's important to keep to high standards. In a real-world project where a lot is at stake, you want to avoid the situation when different labelers assign different classes to ambiguous content.
6.Use Kili's KPIs to compare the model vs. ground truth (human annotations) In our project, there are only two possible IoU scores we can have per asset: either 50% for differing results or 100% for aligned results. We just divide one by the number of selected categories for an entry. If both the LLM and the human labeler agree on the tag, your score will be 100% (one entry / one tag for this entry). If both the LLM and the human tagger have a different tag, your score will be 50% (one entry / two tags for this entry)
7.Fine-tuning the base model In our situation, the model gave us a score of 16%. Of course, we need to fine tune this. OpenAI already provides a fine tuning API. For this, you must provide a list of individual prompts and their associated output.
8.Validate the fine-tuned model - As what we've done in step 6. We will compare the model's performance by generating new predictions and benchmarking it against human labeling. After calculating the IoU, we arrive at 19%. This shows us that we're heading in the right direction, but we still need plenty of work.
9.Repeat steps 4 - 8 - As we've discussed, fine-tuning may need additional data and iteration until you are satisfied with the results. And that is how you fine-tune an large language model via Kili Technology!
Large Language Models fine-tuning: final thoughts
Large Language Models (LLMs) have become a cornerstone of modern natural language processing, enabling unprecedented performance levels across a range of language tasks. Fine-tuning pre-trained LLMs has emerged as a powerful technique for adapting these models to perform specific tasks with high accuracy, even when labeled fine-tuning datasets are small. It is clear that fine-tuning LLMs has opened up new possibilities for natural language processing and has the potential to revolutionize the way we interact with language in the years to come.
FAQ on Fine-Tuning LLMs
What are large language models?
Large Language Models (LLMs) are machine learning models that use deep neural networks to learn complex patterns in natural language. They are pre-trained on large amounts of text data and can then be fine-tuned for specific natural language processing tasks, such as language translation, text classification, or text generation. LLMs have significantly advanced natural language processing and have been widely adopted in various applications.
What are fine-tuned models?
Fine-tuned models are machine learning models that have been adapted to perform a specific task using a pre-trained model as a starting point. Fine-tuning involves adding a task-specific output layer on top of the pre-trained model and updating the weights of both the output layer and the pre-trained model on task-specific data to improve performance on the target task.
What are the most famous large language models?
Some of the most famous large language models include GPT-3 (Generative Pre-trained Transformer 3), BERT (Bidirectional Encoder Representations from Transformers), Roberta (Robustly Optimized BERT approach), and T5 (Text-to-Text Transfer Transformer). These models have significantly advanced natural language processing and have been widely adopted in various language tasks, such as text generation, classification, and language translation.
Why is it often desirable to fine-tune large pre-trained language models rather than train a new model from scratch?
Fine-tuning pre-trained language models is often desirable instead of training a new model from scratch due to the computational resources required to pre-train a model from scratch. Fine-tuning allows for faster and more efficient training, utilizing pre-learned representations that can be optimized for a specific task and achieve state-of-the-art results with less data.
Last updated