LLMs Main Concepts Explained
LLMs: main concepts simply explained
5 min read·Nov 30, 2023
Understanding LLMs without Delving into the Specifics.
This article targets people who need to have an overview of Large Language Models, aiming to understand how they work and become familiar with the associated terminology… but who do not have the time (or the need) to delve deeper. Therefore, simplifications will be used to generalise the concept and provide the bigger picture.
Parameters
This is most likely the first thing we hear when discussing LLMs. For example, while the number of parameters for GPT-4 has not been disclosed by OpenAI, it is known that GPT-3 possesses 175 billion parameters.
Other Open Source LLMs, such as Llama 2, have 70 billion parameters, or even fewer, like Mistral, which has 7 billion.
But what are theses parameters?
An LLM functions somewhat like a ‘black box’ that receives a text as input (often referred to as a ‘prompt’) and generates a text output. The mechanism by which they operate involves predicting the next word based on the text that has been provided as input.

Inside the box, there is a type of neural network, a computing system representing layers of interconnected neurons to loosely mimic the human brain.
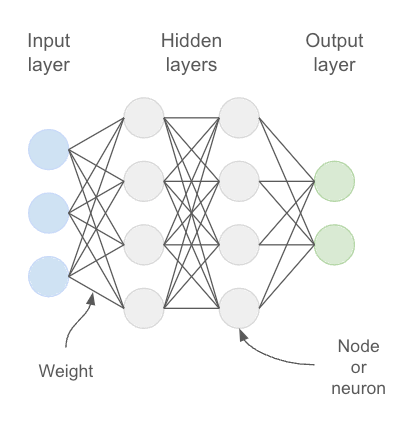
The weight represents the strength of the connection between two neurons. The value of these weights is calculated and adjusted during the training phase where the model is exposed to a vast amount of text data. They form part of the well-known ‘parameters’, but they are not the only ones; another important parameter is the bias. These are a bit less easy to explain without being too technical, but let’s say they are an additional adjustable variable that helps the model fit better. Like weights, biases are also learned during training.
Token
The input text is not processed as is by the LLM, but is transformed into a series of tokens, which are basic units of text. A token can be a word, part of a word, or even a single character depending on the tokenisation method used. For ChatGPT, a rule of thumb is that one token is approximately 4 characters.
Context window / Context length
The context window is the maximum range of text that the model takes into account as input. Generally, it is given in terms of the number of tokens. This is an important parameter because it defines how much information can be passed to the model, which includes both the task that is submitted but also the previous conversations to create the illusion of continuity. For example, the context window of GPT-4 Turbo is 128,000 tokens, while GPT-3.5 Turbo supports only 16,000 tokens.
Transformers
Another concept that you may have heard of is ‘Transformers’, the last letter in GPT, Generative Pre-trained Transformers. This type of neural network, relatively recent (end of 2017), has completely revolutionised the world of Natural Language Processing. The main strength of Transformers lies in handling dependency and context between words to provide more qualitative results. It employs a unique mechanism that the authors have termed ‘self-attention’, the purpose of which is to understand how words in a sentence relate to each other.
(Pre-) Training
As mentioned above, the parameters (weights and biases) are defined during the training phase. To do this, the model requires a large amount of text data that covers a wide range of topics. It also requires significant computational resources, which may take weeks or even months. The information was not provided by OpenAI, but specialists estimate that the cost to train ChatGPT was about 4.6 million US dollars. Therefore, this is clearly something that you cannot do on a regular basis.
If someone tells you that they would like to train an LLM on their company data, this is likely not concerning pre-training, but rather Fine-tuning or Retrieval-Augmented Generation.
In comparison, the training cost of the Open Source LLM Mistral (7 billion parameters) was less than 500,000 US dollars. Such a model can be executed on a high-quality local computer. It is called ‘Pre-Training’ because it is the initial phase of the training. Then, the model — like ChatGPT — is fine-tuned for specific tasks. This aspect is what you may explore should you wish to utilise your company data.
Fine-tuning
Fine-tuning is the stage subsequent to the model’s training. The main idea is to ‘adjust’ the model’s parameters with a smaller and more specific dataset tailored to a particular use case. Various techniques may be used depending on the task for which the model is intended. For instance, questions and corresponding correct answers may be supplied to enable the model to emulate the desired response. Other techniques could focus on paraphrasing, back-translation or reversal curse to improve the quality of the response. This depends on the intended objective. An important point is that fine-tuning necessitates fewer resources and is, of course, less costly.

Retrieval-Augmented Generation — RAG
RAG is a model architecture that allows the incorporation of information that the LLM was not trained on. This can be particularly useful in situations where the model lacks knowledge of a specific domain, such as developments occurring after the pre-training phase, enabling it to accurately answer questions related to that domain.
The best way to illustrate this is by imagining that I ask you a question about the essential stages of winemaking, while simultaneously providing you with the book and the specific page where the answer can be found.
RAG does not change the model’s parameters but does complement fine-tuning. It can be quite remarkable in its capacity to generate more informed and accurate responses.
Last updated