Open-Sourced Training Datasets for LLMs
Open-Sourced Training Datasets for Large Language Models (LLMs)
Table of Contents
Conclusion: You Reap what you Sow
Additional Reading
The emergence of large language models (LLMs) sparks revolutionary transformation in various industries. While ChatGPT has impressed the public with its ingenious take on poetic writing, organizations are adopting deep learning AI models to build advanced neural information processing systems for specialized use cases.
The benefits that LLMs like GPT, LLaMA, and Falcon bring promise efficiency, cost-reduction, and collaborative-friendly business environments. Yet, few question the factors that enable large language models to perform exceptionally in text generation and other natural language processing tasks; or to excel in other respective domains they are deployed in.

In this article, we’ll explore the importance of datasets that AI companies use to train their models. We will also discuss data pre-processing techniques and the ethical challenges of choosing a large language model dataset for training AI models.
Why are datasets important in training LLMs?
As popular as they are, large language models rely on the training datasets they learn on. LLMs consist of multiple hidden layers of deep neural networks, which extract and train their parameters from a significant amount of data sources. If you train LLMs with questionable datasets, they will be impacted by performance issues like bias and overfitting. Conversely, training a deep learning model with high-quality datasets enables a more accurate and coherent output.
Leading organizations have realized that good language modeling needs more than state-of-the-art machine learning models and training methods. Curating and annotating a diverse training dataset that fairly represents the model’s domain is equally important in implementing neural network artificial intelligence solutions in various industries.
For example, Bloomberg trained a transformer architecture from scratch with decades-worth of carefully curated financial data. The resulting BloombergGPT allows the financial company to empower its clients and perform existing financial-specific NLP tasks faster and with more accuracy. Likewise, HuggingFace has developed a programmer-friendly model StarCode, by training it on code in different programming languages gathered from GitHub.
Common challenges when preparing training datasets
Machine learning teams face considerable challenges when curating datasets to train AI models. For example,
Data scarcity in some domains results in imbalanced datasets that affect the model’s ability to infer appropriately. Similarly, preparing a diverse dataset proves challenging in certain use cases.
Training a large language model requires an enormous size of datasets. For example, OpenAI trained GPT-3 with 45 TB of textual data curated from various sources.
Organizations must secure datasets containing sensitive information from adversarial threats to protect users’ privacy and comply with industry regulations.
Data annotation is required when fine-tuning LLMs for downstream tasks. When performed manually, organizations must manage the cost of hiring large teams of human labelers and factor in possible annotation errors.
Data labeling platforms like Kili Technology help organizations overcome hurdles when preparing datasets for machine learning projects. Our software provides automated labeling tools that improve annotation efficiency and reduce the number of human-generated errors.
Popular Open Source Datasets for Training LLMs
These open-source datasets are pivotal in training or fine-tuning many LLMs that ML engineers use today.
1. Common Crawl
The Common Crawl dataset comprises terabytes of raw web data extracted from billions of web pages. It releases new data files that the crawler obtains each month. Several large language models, including GPT-3, LLaMA, OpenLLaMa, and T5, were trained with CommonCrawl.
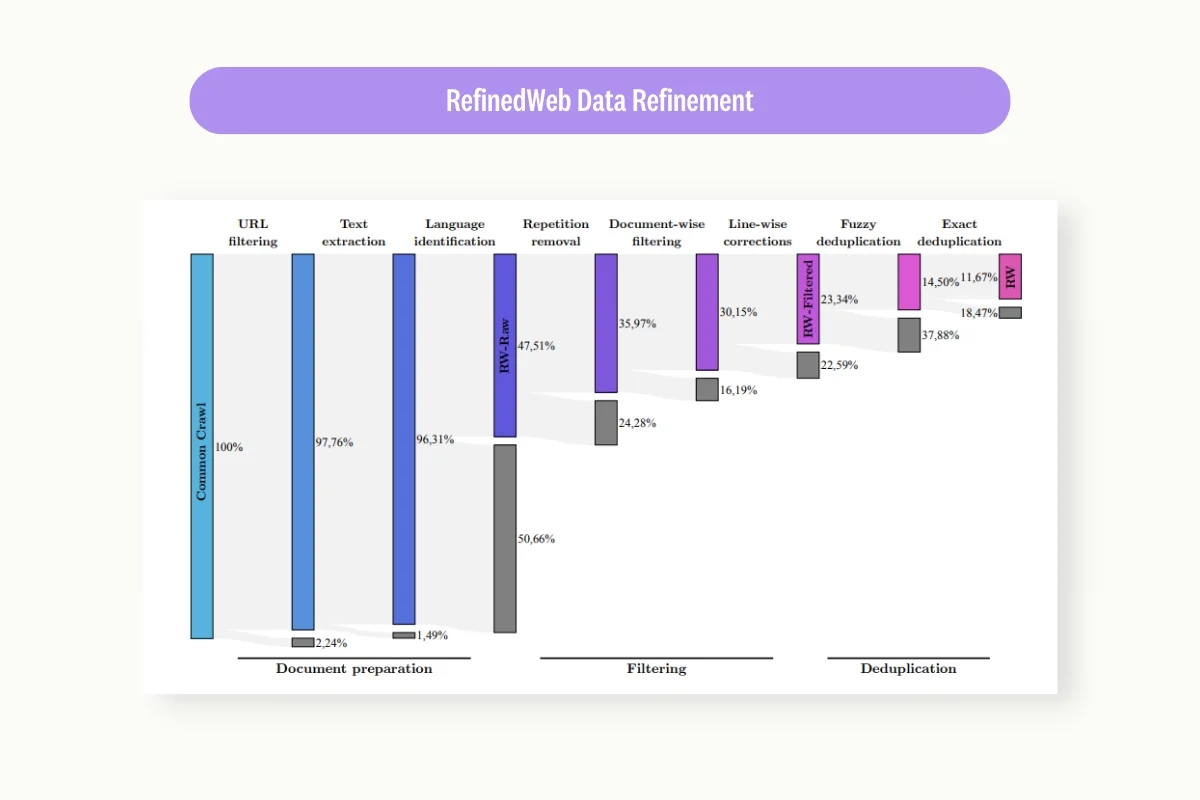
2. RefinedWeb
RefinedWeb is a massive corpus of deduplicated and filtered tokens from the Common Crawl dataset. In natural language processing (NLP), a token is a unit of text that is meaningful to the language being processed. Tokens can be words, punctuation marks, or other symbols. The dataset has more than 5 trillion tokens of textual data, of which 600 billion are made publicly available. It was developed as an initiative to train the Falcon-40B model with smaller-sized but high-quality datasets.

Source: The Pile
3. The Pile
The Pile is an 800 GB corpus that enhances a model’s generalization capability across a broader context. It was curated from 22 diverse datasets, mostly from academic or professional sources. The Pile was instrumental in training various LLMs, including GPT-Neo, LLaMA, and OPT.
4. C4
C4, which stands for (Colossal Clean Crawled Corpus), is a 750 GB English corpus derived from the Common Crawl. It uses heuristic methods to extract only natural language data while removing all gibberish text. C4 has also undergone heavy deduplication to improve its quality. Language models like MPT-7B and T5 are pre-trained with C4.
Source: HuggingFace
5. Starcoder Data
Starcoder Data is a programming-centric dataset built from 783 GB of code written in 86 programming languages. It also contains 250 billion tokens extracted from GitHub and Jupyter Notebooks. Salesforce CodeGen, Starcoder, and StableCode were trained with Starcoder Data to enable better program synthesis.

Source: Jack Bandy
6. BookCorpus
BookCorpus turned scraped data of 11,000 unpublished books into a 985 million-word dataset. It was initially created to align storylines in books to their movie interpretations. The dataset was used for training LLMs like RoBERTA, XLNET, and T5.
7. ROOTS
ROOTS is a 1.6TB multilingual dataset curated from text sourced in 59 languages. Created to train the BigScience Large Open-science Open-access Multilingual (BLOOM) language model. ROOTS uses heavily deduplicated and filtered data from Common Crawl, GitHub Code, and other crowdsourced initiatives.
8. Wikipedia
The Wikipedia dataset is curated from cleaned text data derived from the Wikipedia site and presented in all languages. The default English Wikipedia dataset contains 19.88 GB of vast examples of complete articles that help with language modeling tasks. It was used to train larger models like Roberta, XLNet, and LLaMA.
9. Red Pajama
Red Pajama is an open-source effort to replicate the LLaMa dataset. It comprises 1.2 trillion tokens extracted from Common Crawl, C4, GitHub, books, and other sources. Red Pajama’s transparent approach helps train MPT-7B and OpenLLaMA.
Why Data Preprocessing is Important when Using Open Source Datasets
Never assume that open-source datasets are optimal for training deep learning models. As comprehensive as they are, such datasets often contain redundant, missing, or improperly formatted data that a deep neural network couldn’t process. This draws our attention to data processing.
Data preprocessing is a step that ML teams take to ensure the model trains with clean and consistent data. In practical AI development, language models have a low tolerance for data outliers. An outlier is a data point that differs significantly from other observations. Outliers can be problematic for machine learning models because they can skew the results of the model. For example, a language model that is trained on a dataset with a few outliers may learn to associate those outliers with the wrong words or phrases. This can lead to the model generating incorrect or nonsensical text.
If you apply open-source datasets as they are, the language model will extract, learn and embed the noise within. As a result, the model training process and eventual performance suffer in several aspects.
The presence of redundant data prolongs the time it takes to train a model, which increases computational resources and costs.
Data anomalies might lead to erratic model behavior when exposed to real-world data.
When you forgo data preprocessing, performance issues such as underfitting or overfitting might occur.
So, it’s essential to preprocess your datasets, whether they’re downloaded from sources we listed or curated from your internal databases.

Data Pre-Processing Techniques
We share several common data preprocessing techniques that help you prepare clean, consistent, and quality training datasets.
Cleaning and normalization
Data cleaning removes noisy data or outliers from the raw data. When doing so, ML teams use techniques like binning and regression to filter out noise from the training data. Then, they cluster similar groups of data and remove outliers that don’t belong to any. For example, Technology Innovation Institute uses RefinedWeb, which applies extensive data cleaning, such as URL filtering and deduplication, to train a high-performing Falcon-40B model.
Normalization is helpful to ensure features in datasets are uniformly structured to a common scale. When normalizing data, ML engineers use techniques like min-max scaling, log transformation, and z-score standardization. Normalized data are distributed over a narrower scale, which enables a model to converge faster. In this study, data science researchers have shown that normalizing datasets can improve multiclass classification by up to 6%.
Tokenization and vectorization
Tokenization and vectorization are closely related data preprocessing methods that enable NLP models to extract features from textual sources. Tokenization segregates words or phrases in a sentence into separate textual entities or tokens organized as n-grams. An n-gram is a contiguous sequence of n items from a given sample of text or speech. The items can be letters, words, or base pairs according to the application. N-grams are used to group words together to be processed as a single unit. This can help to improve the accuracy of NLP models by reducing the number of unique tokens that need to be considered.
Meanwhile, vectorization, or word embeddings, is a process that assigns each token a unique number. Common vectorization techniques include bags of words, Term Frequency–Inverse Document Frequency (TF-IDF), and Word2Vec. In this paper, researchers found that applying TF-IDF improved the accuracy of a sentiment analysis model.
Handling of missing data
When your dataset contains missing values, you can either remove or replace them. Removing missing or null data is straightforward but decreases the available data to train the model. Alternatively, impute or replace the data with arithmetic approximation such as mean and median or regression techniques to predict the likely values. Machine learning-driven imputation techniques like missForest and the k-nearest neighbor have shown promising in a comparative study.
Data augmentation
Data augmentation allows you to overcome the limitations of dataset scarcity by transforming existing datasets into new and realistic ones. Because of its cost-efficiency, data augmentation is commonly used when training machine translation and computer vision models. For example, applying transformation methods like flipping, rotating, and scaling enables ML teams to create sufficient datasets for disciplines like medical imaging. Deep AutoAugment is one of the latest efforts to improve data augmentation performance benchmarked with ImageNet.
Ethical Considerations and Challenges When Applying Datasets in Machine Learning
As LLMs usage becomes increasingly prevalent, the spotlight now shines on ethical concerns around the models, as some have reportedly exhibited bias when making predictions. For example, researchers discovered that an AI-powered automated captioning feature on a popular video platform performs less accurately when a Scottish women's accent is chosen.
While model bias may occur because of the model’s architecture, such incidence is equally likely caused by underrepresentation in the training data. For example, ML teams need help creating sufficiently large and diverse datasets for implementing AI systems in Europe. There, the GPDR regulation limits the type of healthcare data one can assemble to train deep learning models.
The dataset's quality has vast implications for the model that trains on it, especially as it can cause undesirable behaviors in AI systems. MIT researchers permanently removed a dataset that caused AI models to describe people with potentially degrading terms. Such abusive behaviors happen because researchers fail to filter racist and sexist labels of images when compiling the dataset.
Besides ensuring fairness, ML teams must strive to safeguard data privacy as AI models gain access to enormous amounts of data. Industries that manage sensitive data, such as healthcare and finance, are particularly concerned about the lack of explainability and data risks that deep learning models might pose. Apple’s recent move to ban its employees from using ChatGPT underscored the risk of leaking confidential data.
Preventing data leakages, whether intentional or not, requires a coordinated effort in policy compliance, data security measures, and software development best practices. It’s imperative to secure the entire ML pipeline, including data labeling tools, from breaches. In this sense, organizations choose Kili because of the security measures our platform provides.
How Datasets are used in Fine-Tuning and Evaluating LLMs
While open-source datasets contribute to the birth of many large language models and their variants, they are equally relevant in other machine-learning tasks applied to a pre-trained model. As you might have realized, pre-trained models cannot infer reliably beyond the data distribution they were trained on. Without further fine-tuning, you can’t use a general language model like GPT-3 for downstream tasks.
Fine-tuning a pre-trained model enables it to learn domain-specific knowledge and unique instructions while maintaining its linguistic capabilities. For example, Google AI used instruction fine-tuning to develop MedPaLM from its base model PaLM. In instruction fine-tuning, the model is trained on a set of examples that are prefixed with instructions. The instructions tell the model what kind of response is expected. For example, an instruction might be "Answer this question in a complete sentence.” The dataset used for fine-tuning is called MultiMedQA and consists of over 100,000 questions and answers from various sources, including the US Medical Licensing Examination (USMLE), PubMed, and clinical trials.
Annotated datasets are also helpful in evaluating a model after fine-tuning. Before deploying the model, ML teams compare its performance with third-party benchmarks to get an objective insight. For example, you can evaluate a model’s tendency to hallucinate with HaluEval, which contains 35,000 question-answer pairs for general and task-specific scenarios. Hallucination refers to the phenomenon where a language model generates text that is incorrect, nonsensical, or not based on the input given. Meanwhile, BOLD was developed by Amazon to measure fairness across different domains.
Language models must also be able to infer with strong confidence and consistency in the domain it was trained for. Hence, ML engineers feed the model with a ground truth test dataset to ensure it can replicate its training results. For instance, IBEM is an open-source ground truth dataset that helps evaluate a model’s capability in finding mathematical expressions.
Stay tuned for more blogs about applying datasets for evaluating and fine-tuning LLMs.

Create smarter LLMs with your datasets
The best LLM for your team is one fine-tuned with your data. Our platform empowers start-ups and enterprises to craft the highest-quality fine-tuning data to feed their LLMs. See for yourself.

Conclusion: You Reap what you Sow
As harsh as it sounds, a deep learning model is only as good as the datasets it trains on. Likewise, organizations seeking to fine-tune a model for domain-specific purposes must prioritize quality and well-annotated datasets. Otherwise, they will be disappointed by the inaccuracies the model displays.
We’ve shared several common open-source datasets that you can use as a foundation to train your model. However, don’t neglect the preprocessing techniques we discussed to ensure optimal performance. Noise and anomalies in datasets can creep into the model and spark various performance issues.
Besides navigating ethical challenges, preparing ground-truth datasets is also a demanding effort for ML teams. Coordinating labelers, reviewers, and domain experts to label a sizable dataset accurately is time-consuming. Kili provides automated labeling tools that help your team to annotate more efficiently and collaboratively.
Last updated